This becomes important when using models such as the producer-consumer.
Critical Section Problem
This is a problem that deals with how to solve race conditions and manipulate data in the critical section safely.
Solutions to this problem should ensure:
Mutual Exclusion: Only one process is allowed in the critical section at one time.
Progress: Selection of a process should be fair, and the decision cannot be postponed indefinitely.
Bounded Waiting: There should be a fixed amount of time it takes for a process to access the critical section.
It should also ensure deadlocks do not occur
Note
Bounded waiting is not usually measured in time but rather in the number of processes ahead of the current one.
Additionally these steps must be followed by a concurrent mechanism to prevent race conditions:
Requesting permission to enter the critical section
Indicate when leaving the critical section
Only permitting a single process at a time to the critical section.
Todo
Add section on preemptive vs non-preemptive kernels
Petersen's Solution
This is software solution to the #Critical Section Problem which supports two processes. It uses shared variables int turn and boolean flag[2] to indicate which process can access the critical section.
flag[i] indicates which processes is currently in the critical section. If flag[0] is set, then we know that p0 is currently in the critical section. turn indicates that a process wants to enter the critical section.
Process 0:
do {
flag[0] = TRUE;
turn = 1; // Turn can be 1 or 0
while (flag[1] && turn==1); // Wait while p1 is in the critical section
// critical section
flag[0] = FALSE;
// remainder section
} while(TRUE)
Process 1:
do {
flag[1] = TRUE;
turn = 0; // Turn can be 0 or 1
while (flag[0] && turn==0); // Wait while p0 is in the critical section
// critical section
flag[1] = FALSE;
// remainder section
} while(TRUE)
Notes
Best supports two processes (can support more but difficult)
Assumes the LOAD and STORE instructions are atomic
Assumes that memory and accesses are not reordered
Less efficient than hardware approaches (for processes)
Lock-Based Solutions
This is a general solution to the critical section problem, and can be implemented in any number of ways.
The problem with many #Lock-Based Solutions is with busy waiting or spinlocks. This means the CPU is not doing any meaningful work when a process is given a time slice and it does not let any other processes do work.
There are no truly "concurrent" processes on these systems. So to prevent interleaving of instructions on a critical section, system interrupts can be disabled.
This is not a very safe or efficient as all types of interrupts, both software and hardware, have to be disabled. This also requires a lot of overhead.
Multi-Processor Lock-Based
As mentioned before disabling interrupts is not very safe or efficient. This is where hardware support in the form of atomic instructions become useful.
bool TestAndSet(bool *mutex) {
bool rv = *mutex; // Get the value of mutex (atomic)
*mutex = TRUE; // Lock the mutex
return rv; // Return the value we grabbed atomically
}
Note
This instruction is atomic because getting the value of the mutex is going to be an atomic instruction. All we are returning is the value we grabbed atomically.
We can then implement mutual exclusion by waiting for the mutex to unlock by using TestAndSet.
int mutex = 0;
void unlock(int *mutex) {
*mutex = 0;
}
void lock(int *mutex) {
while (TestAndSet(mutex)); // Wait for the mutex to unlock
}
do {
lock(&mutex);
/* CRITICAL SECTION */
unlock(&mutex);
} while (TRUE);
We can then implement mutual exclusion by waiting for the mutex to .
int mutex = 0;
void unlock(int *mutex) {
*mutex = 0;
}
void lock(int *mutex) {
int key = TRUE;
do {
Swap(&key, mutex);
} while (key == TRUE);
}
do {
lock(&mutex);
/* CRITICAL SECTION */
unlock(&mutex);
} while (TRUE);
Bounded Waiting (Multiprocessor)
do{
waiting[i] = TRUE;
key = TRUE;
while (waiting[i] && key)
key = TestAndSet(&lock);
waiting[i] = FALSE;
/* CRITICAL SECTION */
/**
* NOTE: Instead releases the lock of the process by setting it's wait to FALSE
*/
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j+1) % n; // Grab the "next" waiting process
if (j == i)
lock = FALSE; // Release the own processes's lock
else
waiting[j] = FALSE; // Release the waiting lock on the waiting process
// Remainder Section
} while (TRUE);
These will use hardware instructions although it seems like a software solution. This means all semaphore instructions are atomic.
There are two types of semaphores:
Binary
Counting
Binary Semaphores: Have binary values and are used to provide mutual exclusion.
Info
These are initialized to 0
Counting Semaphores: Have an integer value, and provide access control to some finite resource.
Info
These are initialized to or the number of the finite resource
void sem_init (int *S) {
*S = 1;
}
void wait (int *S) {
while (*S <= 0);
*S––;
}
void signal (int *S) {
*S++;
}
int S;
sem_init (&S);
do {
wait (&S);
/* CRITICAL SECTION */
signal (&S);
} while(TRUE);
Cons
Essentially shared global variables
Semaphores are very low-level constructs
Difficult to use
Used for mutual exclusion AND scheduling
No control of proper usage (use #Monitors instead)
Semaphores (No-Wait)
No-Wait semaphores aim to solve issues with spinlocks and busy waiting.
It involves a modified wait and signal operation with system calls block and wakeup respectively.
Wait
void wait (semaphore *S) {
S–>value––;
if (S–>value < 0) {
// add process to
// S –>list
block();
}
}
Signal
void signal (semaphore *S) {
S–>value++;
if (S–>value <= 0) {
// remove process P
// from S –>list
wakeup(P);
}
}
Warning
This still requires that the wait and signal operations are atomic.
This can be done by disabling interrupts for uni-core processors like with #Uni-Processor Lock-Based solutions.
This can be done with spinlocks or busy waiting with multi-processor systems like with #Multi-Processor Lock-Based solutions.
This does not solve the entire issue but limits spinlocks and busy waiting to just around the wait and signal calls.
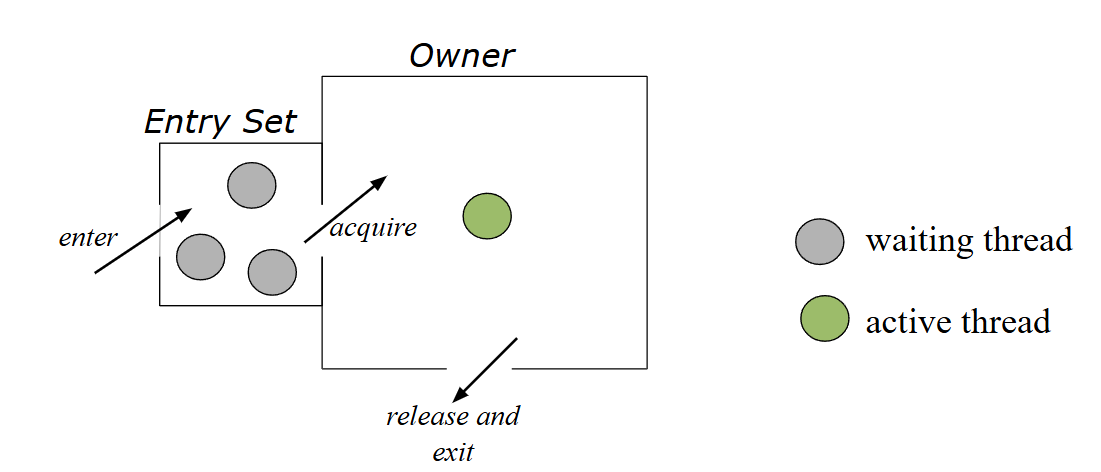
Monitors
These are programming language level constructs that control access to shared data. Code for synchronization is added at compile or interpretation time, it is then enforced at runtime.
Protects the shared data structures inside the monitor from outside access. It also guarantees that only monitor procedures (or operations) can legitimately update the shared data.
Diagram of Monitor usage
Only one thread can execute a monitor procedure at a time
Threads that want to invoke a monitor procedure must wait
When the active thread exits, another waiting thread can enter
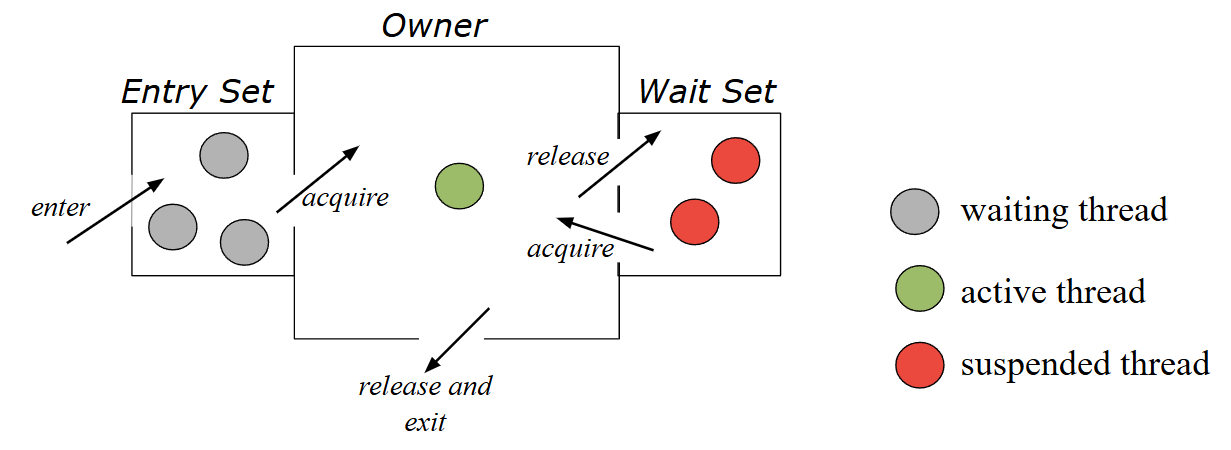
Monitors (Coordinated)
Monitors can use condition variables to coordinate between threads.
A good example is the producer/consumer problem. If producers have not produced anything for consumers to consume, consumers need to wait.
Diagram of Monitor with condition variables for coordination
There are two operations that monitor prodecures can call.
wait
This releases the monitor lock, suspends the thread and puts it into a waiting queue.
signal
Wakes up the next thread in the waiting queue. If there is no suspended process in the queue, there is no effect.
Signal Semantics
Hoare monitors have signal immediately switch from the caller to the waiting thread. The waiter's condition is guaranteed to hold when it continues execution.
Mesa monitors have waiters placed on the ready queue, while the signaler continues. This does not guarantee the waiter's condition may be true when it runs.
A compromise is made where the signaler immediately leaves the monitor, and the waiter resumes operation.
Condition Variables
Important
Condition variables are not Booleans.
The only operations that are valid for conditional variables are wait and signal. They are also not#Semaphores as they have different semantics. But, they can be used to implement each other.
Semantics of Signal and Wait
For wait
Monitor wait blocks the calling thread and gives up the lock
Semaphore wait just blocks the calling thread, and decrements the count
For signal
Monitor signal does nothing if there are no waiting threads
Semaphore signal just increases global variable count, which allows entry to future arriving threads
Problems
The following are problems that can be solved with synchronization.
Bounded Buffer Problem
Readers-Writers Problem
Dining Philosopher's Problem
Definitions
Race Condition
When multiple concurrent execution models are manipulating shared data and the final value of the data relies on order of execution.
Example
Adds and stores the values of counter incorrectly
R1 = load (counter);
R1 = R1 + 1; -- Loads and increments properly
R2 = load (counter); -- Store is interrupted
R2 = R2 – 1;
counter = store (R1); -- Stores incorrect value
counter = store (R2); -- Stores incorrect value
Critical Section
This is a region of shared data that is accessed by many concurrent execution models such as Threads or Processes.
Atomic Instruction
These are CPU instructions that can access and update memory in a single location in one single step (atomic). This usually refers to an Assembly#Instruction Set Architecture (ISA) code.
Semaphore
This is an integer variable and it only accessed using the init(), wait(), signal() operations. These operations are atomic.
Deadlocks
Two or more processes which are waiting indefinitely for and event that can only be caused by one of the waiting processes itself
Starvation
The process is not deadlocked, but never removed from a waiting queue.
Priority Inversion
When a lower priority process is blocking a higher priority process. This can occur when a higher priority process is blocked by a lower priority process that is unrelated to the former's execution.
Solution
The solution is priority inheritance protocol. This essentially lets a higher priority process which depends on a lower priority process temporarily elevate the priority of the lower priority process.
Reference
Kulkarni, Prasad Various Lectures The University of Kansas 2024