Differs from Memory Management as it may not bring the entire program into physical memory at one time.
Overview
Virtual memory is the separation of logical memory from physical memory. This allows for a few key things.
- Virtual memory allows for processes to start running without being entirely loaded into memory.
- Logical address space to be larger than physical address space.
- Address spaces to be shared by several processes.
- More efficient process creation.
- Faster program startup.
- More programs can reside in memory at the same time.
Virtual Address Space
Virtual address space allows for only parts of the program be loaded at a time. This is useful as certain functions or "holes" in the program, i.e. empty heap/stack space, may not be used immediately, or often.
This also allows for shared memory similar to Memory Management#Shared Pages. This can be used to implement some of the following.
- Shared read-only libraries
- Shared memory for IPC
- Parent and child processes can share pages when
fork()is used
Demand Paging
Only bring a page into memory when needed.
- Less I/O needed
- Less physical memory needed
- Faster response/startup
- Allows a logical address space > physical address space
- More applications in memory
- Greater degree of multiprogramming
- Higher CPU utilization and throughput due to the larger number of processes in memory
Some drawbacks of demand paging include:
- Increase in later individual memory access times
- Potential for over-allocation of physical memory
- This is where #Page Replacement comes in
A Lazy Swapper never swaps a page into memory unless needed.
Demand paging has a large overhead. It increases the Effective Access Time (EAT).
Valid-Invalid Bit
Unlike with the use of valid-invalid bits in Memory Management#Memory Protection, the valid-invalid bits for virtual memory mark if a page is/isn't in physical memory respectively.
vindicates the page('s frame) is in memoryiindicates the page('s frame) is not in memory
i can indicate one of two things:
- The page is not a part of the logical address space at all
- The page has not yet been put into physical memory
Generally however, it means there is no mapping from a logical page to a physical frame.
All entries in a page table are set to i by default. If an address translation occurs and the valid-invalid bit is set to i, this cases a page fault.
## Page Faults
Page faults are exceptions. It can be a trap that sends an interrupt to the OS which then decides what to do. Usually this leads to #Page Replacement.
Page Replacement
If currently active processes reference more pages than room in physical memory, pages from active processes may need to be replaced.
Page replacement is needed when a page fault occurs, and there are no free frames to allocate.
The basic steps of page replacement are as follows:
- Find the location of the desired page on disk
- Find a free (victim) frame
- If there is a free frame, use it
- If there is no free frame, use a #Page Replacement Algorithms to find one
- Bring the desired page into the (newly) free frame and update page and frame tables
- Restart the instruction
- Using a modify bit with each frame
- Only copy the replacement page to memory if modified
Ideally the victim frame is a frame that is not currently in use or used very often. This can be approximated by some #Page Replacement Algorithms.
Page Replacement Algorithms
The goal of these algorithms are to get the lowest page fault rate. We don't want to victimize a page that is (frequently) in use.
Evaluation be done with simulation on a particular string of memory page references. Alternatively it can be done by computing the number of page faults on the reference string.
For some replacement algorithms, the page fault rate may increase as the number of frames increases.
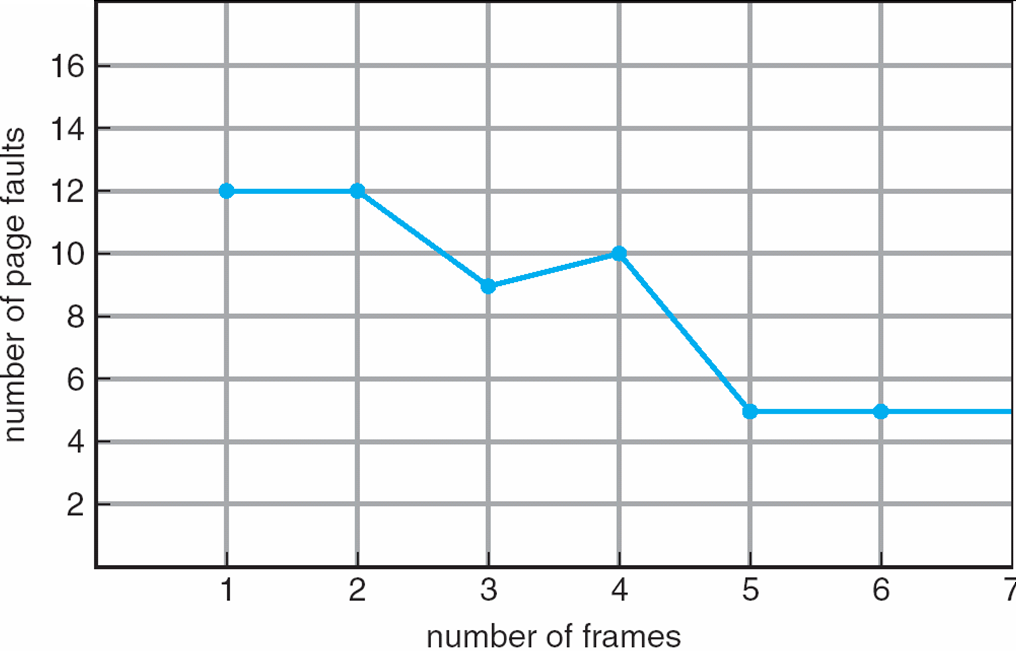
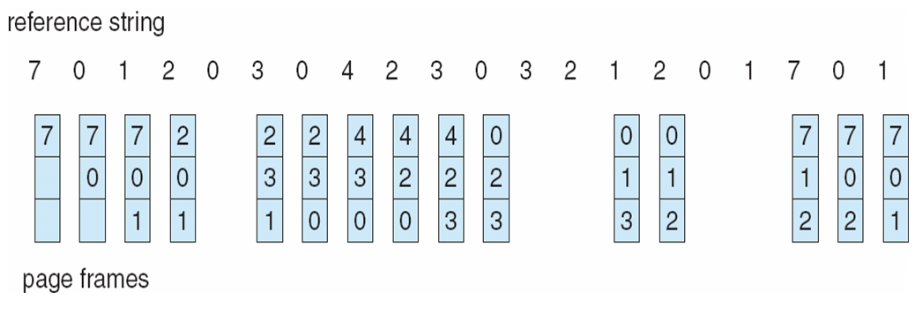
FIFO Replacement
Each page is associated a time when it was brought into memory. If a page needs to be replaced, the oldest page is replaced. This is implemented using a FIFO queue. The new page is pushed back to the end of the queue.
Optimal Page Replacement
This is not a practical algorithm to implement.
This algorithm has the lowest page fault. It replaces the page that will not be used for the longest period. It does not suffer from #Belady's Anomaly but needs future information.
Least Recently Used (LRU)
It usually requires hardware support to be accurate and fast. It does not suffer from #Belady's Anomaly.
This approximates the #Optimal Page Replacement algorithm. It detects and stores when each page is used. It replaces the page that has not been used for the longest period of time. It is generally a good replacement policy.
Counter Implementation has each page table entry hold a time-of-use entry. It copies the current clock into the time-of-use entry with every page access.
To replace it finds the page with the smallest time-of-use. Each memory access to a page triggers an additional write to the time-of-use field.
The reason this is slow is the entire page table must be searched in order to find the page with the smallest counter value. Additionally there is the extra cost of updating counter values even when a page fault does not occur.
This implementation may also suffer from counter overflow.
Stack Implementation keeps a stack of page numbers in a linked list. This moves the page to the top of the stack when referenced.
It finds a replacement from the bottom of the stack. Each update is more expensive due to stack operations.
This reduces the cost of searching because there is no search for replacement. However there is still overhead for managing the linked list stack. It still requires hardware support to be efficient.
LRU Approximation
Because #Least Recently Used (LRU) requires hardware support in order to function efficiently. LRU approximation algorithms are used instead to reduce the amount of hardware support.
The Reference-Bit Algorithm associates a reference bit with each page. The bit is set when a page is referenced, and cleared periodically.
Replacement occurs by finding a reference bit with a value of 0 (if one exists).
It cannot store the order of accesses in one bit. That is where the Record reference-bit algorithm comes in.
The Record Reference-Bit Algorithm associates each page with an 8-bit field for recording reference bits. At regular intervals the 8-bit field is right-shifted and the reference bit is moved into the highest-order bit.
Replacement occurs by finding the lowest value in the 8-bit field.
The Second-Chance Algorithm is a basic FIFO replacement algorithm that uses a single reference bit associated with each page. The FIFO is a circular queue and also has a pointer which indicates the next replacement page.
The replacement page is found if the reference bit is 0. Otherwise, if the reference bit is 1, the page is given "another chance" and the bit is flipped back to 0.
Counting Based Replacement
Put simply, each page is given an a counter based on the number of references made to it.
This can be used to replace the least frequently used page, or the page that has the smallest count.
Alternatively it can be used to replace the page with the largest count. Replacing the page with the largest count may seem counter-intuitive but the idea is that the page with the largest count should be the oldest page and therefore should be replaced.
They are not very popular algorithms
Page Buffering Algorithms
Page buffering algorithms help optimize #Page Replacement by maintaining a list of victim frames. Each frame in the list of victim frames are unutilized. This allows for the swap-out to be delayed to a later time, increasing performance. They may follow one of three schemes.
Scheme 1:
- Bring a new page into one of the victim-frame slots
- Copy-out the replacement page to the correct memory slot
Scheme 2:
- Works similarly to Scheme 1
- Copy-out the modified pages to disk when the paging device is idle
- Replacement is now faster
Scheme 3:
- Remember which page is in each victim frame
- If needed page is in one of the victim frames, the use it directly
- Works well when replacement algo replaces a page that is needed right after
For Scheme 1, memory access to the new page can occur as soon as the new page has been copied into a victim-frame slot.
Allocation of Frames
The minimum number of frames is dependent on the Assembly#Instruction Set Architecture (ISA). For example some instructions such as load or store require two memory addresses, one for the instruction and one for the memory reference.
The maximum number of frames is technically arbitrary. A process could use all the frames available in a system, but that would underutilize the CPU and not allow for any other processes to start. Instead one of two simple algorithms can be used.
Equal Allocation simply divides the number of frames equally among all processes. e.g. given
Proportional Allocation allocates frames based on a processes' size. It follows this simple formula.
Global v.s. Local Replacement
Global replacement selects a replacement frame from the set of all frames. i.e. one process can take a frame from another. Global replacement is generally slower and less scalable, but generally has a lower number of page faults. This is because the set of all possible frames is larger which means unused frames are likely easier to find.
Local replacement has each process select frames from its own set of allocated frames. Local replacement is more scalable and faster, but may suffer from more page faults as it has a smaller set of frames it works with.
Local replacement may hinder the progress of higher-priority processes by not allowing the higher-priority process to take frames from the lower-priority process.
Non-Uniform Memory Access
When dealing with multi-processor systems it is best to assign frames which are close to the processor running a process in physical memory.
Thrashing
Thrashing occurs when a process spends more time paging than executing. This may occur if memory keeps swapping active pages in and out. It leads to a very high page fault rate.
Thrashing is a result of not having "enough" frames allocated to it.
Thrashing is more likely to increase with an increasing degree of multiprogramming.
Working-Set Model
Thrashing can be prevented by giving the process as many frames as it needs. This is done with the Working-Set Model. It is based on the locality model of process execution. The number of frames required for each execution is called the working set.
Looking at the model below, where page faults spike mark the beginning of a new program or phase. This also denotates where the working set of each program starts.
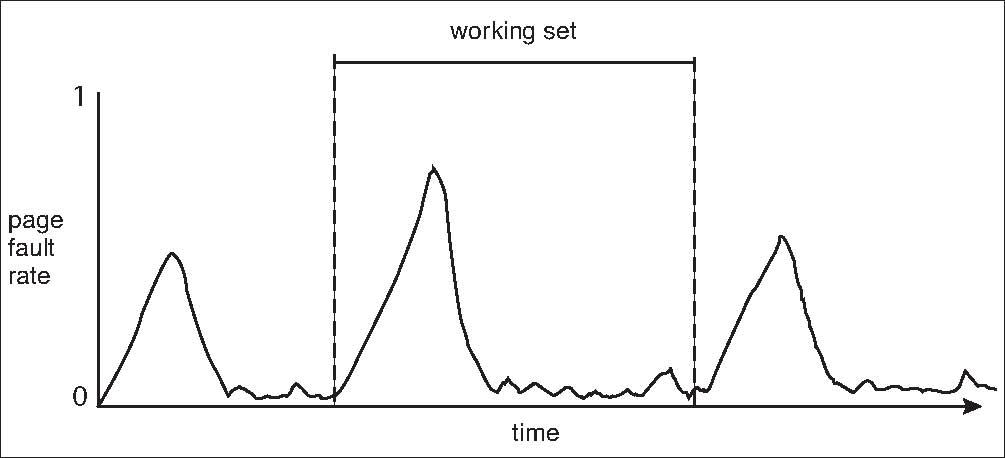
Page-Fault Frequency Scheme
Since the working-set model requires a lot of assumptions and is complicated, the page-fault frequency scheme can just monitor page faults per process to make sure they are within acceptable limits.
This scheme establishes an "acceptable" range of page-fault rates and routinely measures page fault rates per-process. If the page-fault rate is greater than the upper-bound of the range, the process is given frames or suspended. If the page-fault rate is smaller than the lower-bound the number of frames allocated to the process is decreased or more processes are added.
Memory-Mapped I/O
Using memory-mapped I/O is beneficial when reading/writing large amounts of data from a file. It uses #Demand Paging to read in large chunks of the file to memory. All subsequent read/writes are treated as memory accesses. This can be beneficial as the overhead of using system calls such as read and write are reduced, and larger chunks of data can be copied or read at one time due to the size of the pages in memory.
This can also be used to implement Processes#Shared Memory.
Using memory-mapped I/O can also reduce the complexity of the circuitry and hardware to manage I/O devices.
Allocating Kernel Memory
Kernel memory is often allocated from a free pool. It does not use demand paging for a multitude of reasons.
- Some kernel memory needs to be contiguous
- DMA (Direct Memory Access) for I/O devices
- OSes are large pieces of software, it knows its own data structures and often can manage its own memory better in order to prevent internal fragmentation.
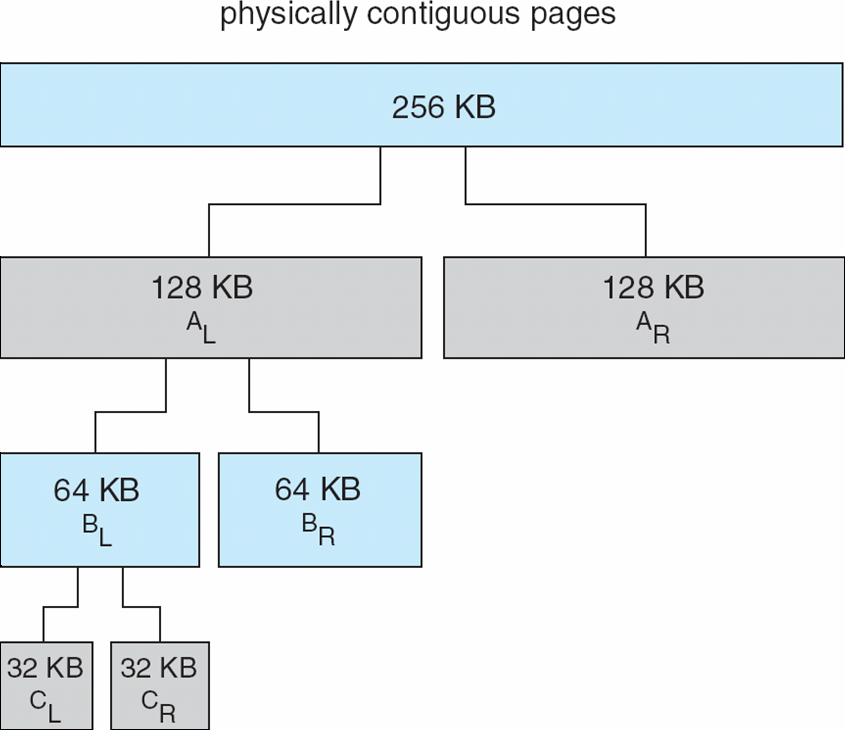
Buddy System
The buddy system we discuss uses the power of 2 allocator. This responds to all requests for memory in blocks sized to the power 2. It rounds up to the next highest power of 2 and splits chunks to next lowest powers of two to best-fit the requested size.
e.g. a block of 27KB is requested, the closest power of 2 larger than 27 is 32. So, 32KB will be allocated, with 9KB lost to internal fragmentation.
Slab Allocator
A slab allocator consists of caches and slabs. A slab contains several contiguous pages while a cache contains one or more slabs. There is a cache for every unique data structure in the kernel
Copy-on-Write Process Creation
Copy on write allows for both parent and child processes to initially share the same pages in memory. The pages are marked as copy-on-write (COW). If the process modifies a shared page the page is then copied. Only modified pages are copied.
This allows for more efficient process creation as only modified pages are copied. Free pages are allocated from a pool of zeroed-out pages.
Reference
- Kulkarni, Prasad Various Lectures The University of Kansas 2024