Overview
Memory consists of a large array of bytes. The memory and registers are the only forms of data storage that the CPU can directly access.
Accessing memory is slow for a multitude of reasons. It may take multiple clock cycles to reach memory. The CPU's physical distance to memory and use of DRAM (slower RAM) are just a few examples of why accessing memory is slow. A cache (L1-3) sit between main memory and CPU registers to speed up this process.
Memory management is important as memory is finite. Only the CPU can access memory and registers directly. In order for other programs and devices to access memory they must do so through the OS.
Logical V.S. Physical Address Space
A logical address space is always bound to a physical address space. The logical address (virtual address) is generated by the CPU. The logical address is converted to the physical address using the MMU.
Logical and physical addresses are the same for #Compile Time Binding and #Load Time Binding. They differ for #Execution Time Binding.
Memory-Management Unit (MMU)
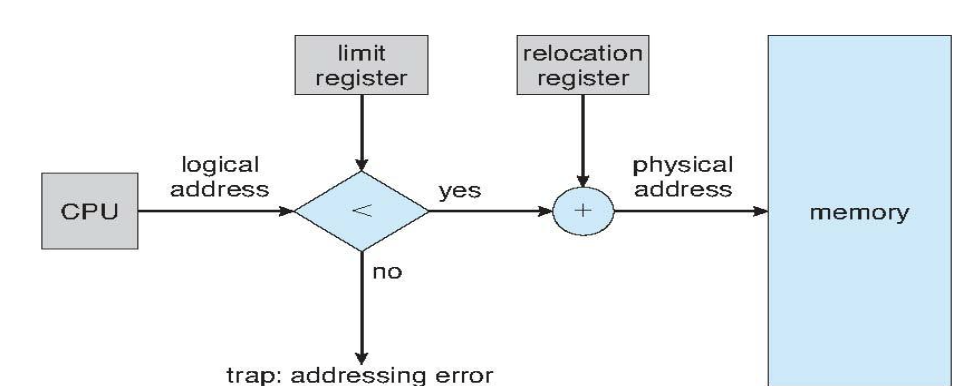
This is a hardware device that maps a virtual address to a physical address. Each logical process starts from 0. The base memory is placed in a special register, the relocation register, and offset by the logical address. The max process (virtual) address is stored in the limit register.
The MMU maps logical addresses to physical addresses dynamically. It also checks to see if logical addresses are within the valid range (within the bounds of the base and limit system).
There is some overhead in converting logical addresses to physical addresses. The MMU relieves some of the cost as it is a hardware solution.
Loading Programs
Static Loading
Static loading puts the entire program in memory before the program starts running. The program size is limited by the size of the memory.
Dynamic Loading
Dynamic loading works by loading certain sections of the program in as the program was executing. This only worked on older systems when two functions did not work together. This is because if two functions were run together and one function was loaded and one was not the program would fault.
Linking Programs
Static Linking
Static linking includes all libraries into the final binary image. This may result in an extremely large binary if many libraries are used, and makes it difficult to swap out libraries.
Many copies of library code may reside in memory at one time.
Dynamic Linking
This is when linking of libraries is postponed until execution time. A small piece of code, called a stub, is used to locate the appropriate memory-resident library routine.
With dynamic linking only one binary is loaded into memory. All other programs which have dynamically linked the binary will access the same location in memory to use the library.
Dynamically linked library files are notated with .so in UNIX Linux (shared object) and .dll in Windows (dynamically linked library).
Swapping
Swapping moves a process from main memory to a backup store. This store is usually located on a partition in an ssd/disk or some other persistent storage device with large capacity.
Processes may be swapped for the following reasons:
- There is no free memory for a new process
- A process needs more physical memory than is available
Swapping is usually costly. If swapped out memory needs to be brought back in to main memory frequently, memory thrashing can occur.
More on Virtual Memory#Thrashing
Contiguous Memory Allocation
Each process is assigned a single contiguous region of memory. This allows for multiple processes to reside in memory at one time.
Processes must still be protected from each other
Protection of processes should be hardware supported and is done with #Base & Limit Registers and #Logical V.S. Physical Address Space. It protects user processes from each other and the OS from user processes.
Contiguous memory allocation uses the multiple-partition method.
This method essentially looks for holes in memory, which are spaces of free partitions, and places processes in holes large enough to fit each process. The OS maintains information about allocated partitions, and free partitions.
The multiple-partition method can use the following schemes:
- First-fit - Allocate the first hole large enough
- Best-fit - Allocate the smallest hole large enough
- Worst-fit - Allocate the largest hole large enough
Best-fit must search the entire list of available memory, and produces the smallest hole.
Worst-fit produces the largest hole.
First-fit and best-fit are usually better in terms of performance and storage requirements when compared to worst-fit.
First-fit is generally the fastest.
Paging
The solution to #External Fragmentation and #Compaction is paging.
This still does not solve the problem of #Internal Fragmentation.
Paging allows for the physical address space of processes to be non-contiguous. This is commonly used in many OSes. This usually depends on hardware support.
Paging divides physical memory into fixed-size blocks called frames. It also divides logical memory into the fixed blocks of the same size called pages. The OS keeps track of all free frames. It also requires a #Page Tables to translate logical addresses to physical addresses.
Block sizes are usually powers of 2 because of the speed advantages of manipulating numbers to the power of 2.
Paging Address Translation
This uses a special logical address. The page size d determines the number of bits required to specify page offset. The remaining number of bits in the logical address specify the page number.
Page Size ->
Offset ->
Page Number ->
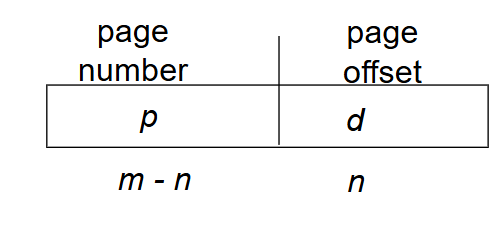
The offset is the amount of data a page can hold.
Page Tables
A page table maps logical pages to physical frames.
Page Table Issues
Smaller page sizes reduces #Internal Fragmentation, this is because smaller pages will waste less space. Larger page sizes will reduce the size of the page table. This is because larger pages will incidentally lead to smaller page numbers and therefore smaller tables. Larger pages will also increase the efficacy of disk transfers.
Page sizes are around 4 KB which results in around a 4 MB page table.
Each memory load and store goes through a page table. Page table accesses must be fast to reduce the overhead and latency.
It could be possible to store page tables on hardware registers, but the size of page tables are usually so large its not often feasable.
Each process has its own page table. Which means page table switching on each context switch must be fast. Most modern computers allow for large page tables, so the page table is kept in main memory and a register points to the location of the page table in memory.
Page Table Implementation
Page Table Base Register (PTBR)
This points to a page table. Only this register is updated on each context switch.
Every load/store instruction requires two memory accesses. One for the page table and one for the data/instruction.
Translation Look-Aside Buffer (TLB)
This is a very important cache, likely more so than L1, L2, etc. It is also very power intensive as it uses simultaneous lookups for the page number.
This is a cache which holds popular page table entries. Access to the TLB should be fast, which is why it usually exists on the CPU. It also uses an associative cache.
Each process should have its own page table. This means that on a context switch the OS changes the PTBR pointer, it may need to purge the TLB (cache invalidation).
This uses address-space identifiers (ASIDs) in each TLB entry.
Memory Protection
If a process does not use all the entries in a page table. The unused page table entries must be marked as invalid or "I".
Memory protection is implemented by associating a protection bit with each frame.
Assuming the max process address is in the middle of some page number, the OS can choose whether or not to mark addresses beyond the max address as invalid. The valid/invalid bit only marks entire frames as valid or invalid.
Shared Pages
Paging allows for the possibility of shared code.
One copy of read only (reentrant) code is shared among processes. Each process has private data.
Significant reduction in memory usage is possible with this.
Structure of the Page Table
There are many simple and complex ways to structure a page table. Simple page table structures may not account for large page tables however.
The following are some structures that page tables may use:
- Hierarchical Paging
- Hashed Page Table
- Inverted Page Table
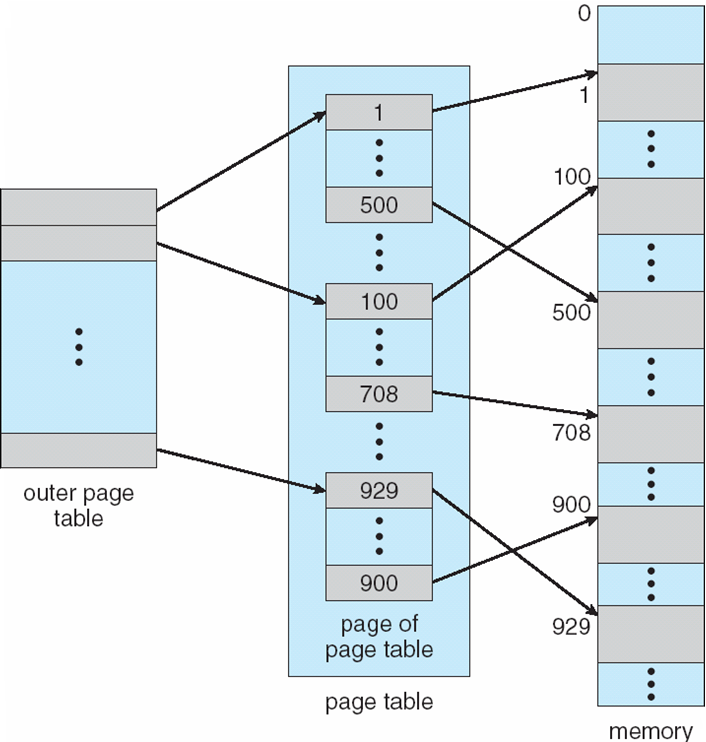
Hierarchical Page Tables
It may be necessary, sometimes, to divide a page table into non-continuous entries. This can happen for page tables with a logical address spaces greater than
The goal of hierarchical page tables is not to reduce the total size of the page tables, but rather reduce the individual size of the page tables.
It also allows for page tables to be discontinuous in memory.
The basic method requires two types of page tables, an outer page table and multiple inner page tables. The page number is also divided into two halves in order to index the outer and inner page tables.
We can increase the number of 'nested' tables beyond just an inner and outer table. However each level requires a memory access. That means for every memory access required by the CPU, given n levels, there are n+1 memory accesses. This increases the time cost of memory accesses and is inefficient.
Two Level Scheme
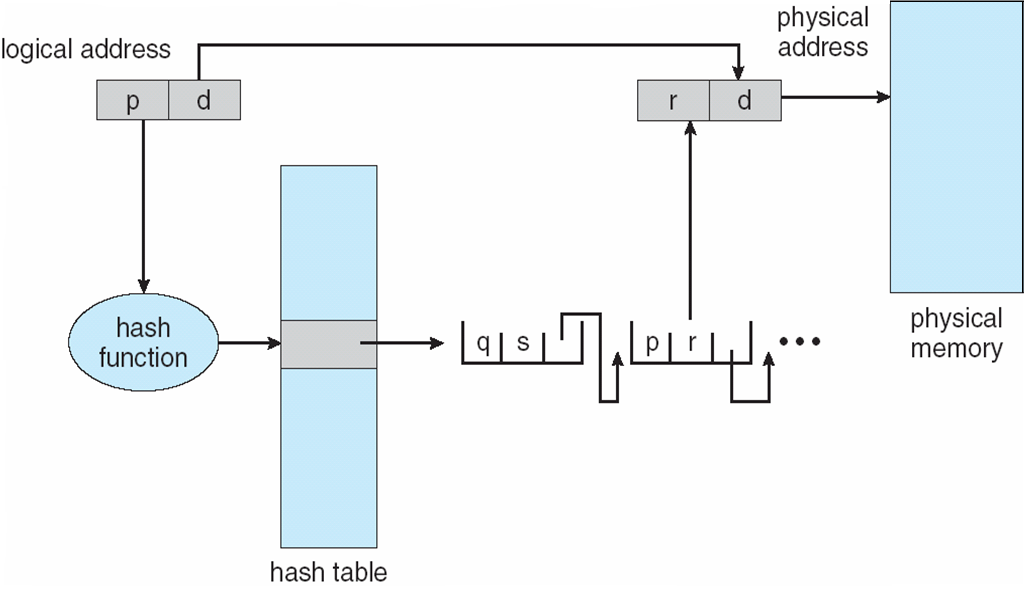
Hashed Page Table
This is useful for page tables with longer than 32 bits of logical address space.
This method takes the page number and puts it through a hashing function to find the index in the hash table. The value at that index points to a linked list that contains page numbers mapped to frame numbers and a pointer to the next element in the list. The list is traversed until the correct page number is found.
The benefit of this method is the ability to determine the size of the table. Because the hash function can be changed, the size of the table can also be changed.
Inverted Page Table
Up until now, page tables have been indexed by the page number and the value is the frame number. The inverted table flips that notion and has indexes represent frame numbers and values represent page numbers.
The inverted page table has an entry for every frame of physical memory. Each entry contains a page number currently residing in that bit of physical memory and information on the process that owns the page.
Unlike normal page tables there is only one inverted page table. This is because there is only one "block" of physical memory.
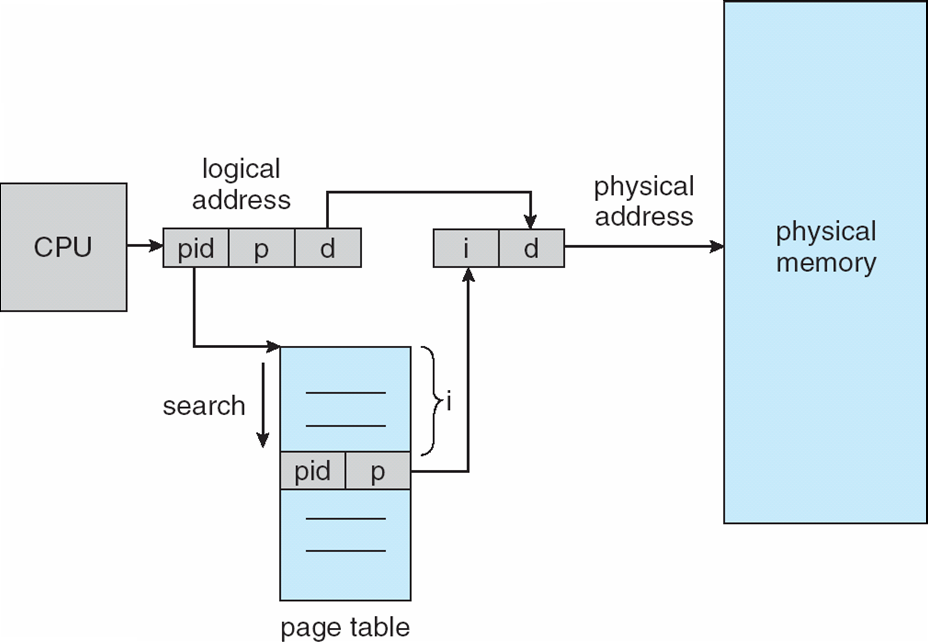
While the inverted page table decreases the memory needed to store each page table, it has other issues.
- A linear search is required to find the correct frame
- There is a substantial increase in search time for every memory access
These shortcomings can be solved with hash tables to limit searches to one or fewer page table entries.
Segmentation
This method divides programs into logical sections (segments) which are used for different semantic purposes. Segments are not of a fixed size, for example the stack segment could be much larger than the program segment. Segments must be in contiguous space but segments do not need to be contiguous with other segments.
Not very widely used today.
It still has the problem of external fragmentation.
Segment Tables
A segment table maps two-dimensional logical addresses. Each table entry has a:
- base: The starting physical address where the segments reside in memory.
- limit: The length of the segment
The Segment-Table Base Register (STBR) points to the segment table's location in memory.
The Segment-Table Length Register (STLR) indicates the number of segments used by a program. e.g. segment
Intel Pentium
The Pentium processor supports #Segmentation and segmentation with paging.
The CPU generates a logical address which is then given to the segmentation unit. A linear address is given to a paging unit which then generates a physical address to use in memory.
Segmentation:
- Used a 32-bit arch
- Max number of segments: 16K
- 8K segments in local descriptor table (LDT)
- 8K segments in global descriptor table (GDT)
- Max segment size: 4GB
- Each segment descriptor: 8-bytes
- Contains segment base and limits
- Each logical address is 48-bits
- 16-bit segment selector, 32-bit offset
- 16-bit segment selector contains
- 13-bit segment number, 1-bit table identifier, 2 bits of protection
- Maps 48 bit logical address to 32 bit linear address
Paging:
- Page size - 4KB or 4MB
- For 4KB pages - two level paging scheme
- Base of page directory pointed to by CR3 register
- 10 high order bits offset into the page directory
- Page directory gives base of inner page table
- Inner page table indexed by middle 10 bits of linear address
- Page table returns base of page
- Low-order 12 bits of linear address used
Definitions
External Fragmentation
This occurs when #Contiguous Memory Allocation is used and the total memory space exists to satisfy a request, but the memory locations are not contiguous.
Solutions to this can include compaction, or allowing for non-contiguous allocation.
Internal Fragmentation
This occurs when fixed sized blocks are used [1]. The size of the block may be larger than the memory required by a process.
The amount of memory lost by internal fragmentation is
b - n
Where
Compaction
This moves allocated block to place all holes together. Compaction is possible only if relocation is dynamic.
Base & Limit Registers
The OS can protect Processes from each other using base and limit registers to define a range of valid addresses a process is allowed to use. The CPU then compares each address generated by the process with the base and bounds registers to determine if the memory access is valid.
Compile Time Binding
If the memory location is known a priori absolute code can be generated. This code has hard coded memory locations in the program binary.
This method requires that the code be recompiled if the starting location changes.
Load Time Binding
Load time address binding generates relocatable code. The allows for code to be compiled once, and placed anywhere in memory.
The loader is what changes the addresses in the binary.
Execution Time Binding
Binding is delayed until runtime. If the process is moved during its execution from one memory segment to another, the OS can change the addresses in the binary.
This requires hardware support for address maps, e.g. #Base & Limit Registers.
Effective Access Time
EAT = (1-p) * memory_access_t + p *
(page_fault_overhead + swap_page_in + swap_page_out + restart_overhead)
Reference
- Kulkarni, Prasad Various Lectures The University of Kansas 2024
Related
Fixed sized blocks are used to reduce the cost of managing extremely small holes. ↩︎